

At the end of the day the IoT boils down to one thing: data.
Collectively, our connected products are estimated to generate upwards of 80 zettabytes (ZB) of data this year. That's 80,000,000,000,000,000,000,000 bytes if you're counting (or the equivalent prepaid data allocation of 160 trillion cellular Notecards!).
While there are myriad cloud platforms to help us interpret and visualize our data, it's becoming increasingly clear that no human-created platform or process will allow us to intelligently distill our data into meaningful insights.
It's 2025, so it's time to turn to AI for a potential solution. While you'll hear a lot more about AI from Blues in 2025, today I'd like to show you one relatively simple way to take your first steps into the AI arena.
 note
noteThe following examples use publicly available LLMs (large language models) from OpenAI. To derive truly intelligent insights, it's likely you'll need a custom LLM trained on your data. This exercise is purely meant as a "first step"!
Starting with Notehub
Let's start this exercise assuming we have at least one active Notehub project that holds data from one or more Notecard devices. In my case I have a long-term project that holds data from numerous Notecards which I use for adhoc exercises and demos.

As a product scales, it's more than likely the data will scale accordingly (if not exponentially). Much of this data is almost unintelligible without some automated means of translation.

At this point with any Notehub project, we are likely already routing data out of Notehub to our cloud platform of choice. Maybe we have a Datacake or Ubidots dashboard that visualizes data segments or issues alerts. Either that or we export event data in CSV or JSON and manually process it offline.
But I'm more curious about what we're missing! Building a cloud dashboard requires us to understand what we want to visualize ahead of time, meaning we could miss anomalous data points or other insights derived from our product data (or even from the metadata generated by Notecard and Notehub about the events themselves).
At a high-level, here is what I'm aiming to accomplish in the remainder of this article:
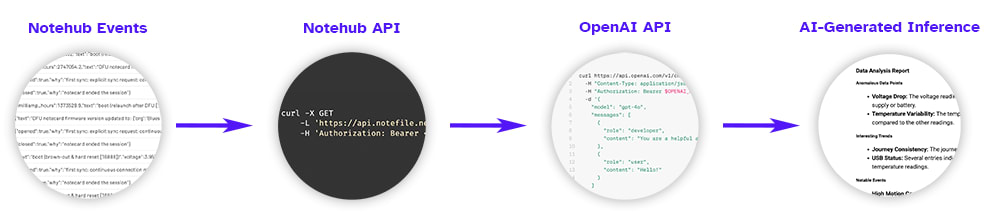
Let's see how we can quickly implement this process.
Use the Notehub API to GET Event Data
Thanks to the Notehub API, we can pull events out of a Notehub project using standard HTTP requests. Let's start by writing a query to GET events using a couple of the provided APIs.
Notehub API Authentication
Every Notehub API request is secured with OAuth bearer tokens. Each token lasts 30 minutes, so it's important to keep that in mind when designing your backend system. Here is an example cURL request for generating a bearer token:
curl -X POST
-L 'https://api.notefile.net/oauth2/token'
-H 'content-type: application/x-www-form-urlencoded'
-d grant_type=client_credentials
-d client_id=your-client-id
-d client_secret=your-client-secretYou don't have to use cURL. You can use your backend programming language of choice to issue HTTP requests and there are Notehub API libraries for Python and JavaScript/Node.js.
The your-client-id and your-client-secret values can be obtained by
creating an OAuth Client in the Settings of your Notehub project, under
the OAuth section.


My programming history is in the .NET world, so I'll provide the C# methods I used to build out this system. Again, there is absolutely nothing here stopping you from using Go, Python, Node.js, etc.
Here is the approximate equivalent of the above cURL authentication request in C#:
protected static string GetAccessToken(string url, string clientId, string clientSecret)
{
string postData = string.Format("grant_type=client_credentials&client_id={0}&client_secret={1}",
Uri.EscapeDataString(clientId),
Uri.EscapeDataString(clientSecret));
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
using (var streamWriter = new StreamWriter(request.GetRequestStream()))
{
streamWriter.Write(postData);
streamWriter.Flush();
}
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
using (var streamReader = new StreamReader(response.GetResponseStream()))
{
string responseContent = streamReader.ReadToEnd();
var json = JObject.Parse(responseContent);
return json["access_token"].ToString();
}
}
}Regardless of how you execute it on the server, the /oauth2/token request
will return JSON that looks something like this:
{
"access_token":"-MZBBWcAyg3HjCJ2u95H9IQnGTQyh380SUwneKiOYKg.EZ012-gePFWQ2uJofFt9HBfxK-kEjAcqi9QTqRNehlI",
"expires_in":1799,
"scope":"",
"token_type":"bearer"
}The value we want is access_token, which we will need to use in the next
Notehub API request.
Pulling Event Data from Notehub
The other Notehub API we care about today is the Get Project Events API. This API allows us to pull all events from our project or limit the results to specific Notefiles and/or date ranges.
Here is an example cURL request that limits returned events based on the
_track.qo and sensor.qo Notefile names, as well as by a date range in which
the event was captured by the Notecard (which are UNIX epoch times):
curl -X GET
-L 'https://api.notefile.net/v1/projects/<projectUID>/events?files=track.qo,sensor.qo&dateType=captured&startDate=1731735891&endDate=1737735891'
-H 'Authorization: Bearer <access_token>'Be sure to consult the Get Project Events API documentation for more details on the individual API arguments.
Here is the method I wrote in C# to pull out all events, limited by Notefile name and date range:
protected static string GetEvents(string accessToken, string projectUID, string notefiles, string startDateUNIX, string endDateUNIX)
{
string url = "https://api.notefile.net/v1/projects/" + projectUID + "/events?files=" + notefiles + "&dateType=captured&startDate=" + startDateUNIX + "&endDate=" + endDateUNIX;
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Method = "GET";
request.Headers.Add("Authorization", "Bearer " + accessToken);
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
using (var streamReader = new StreamReader(response.GetResponseStream()))
{
return streamReader.ReadToEnd();
}
}
}The response is an array of events:
{
"events":[
{
"event":"3dc47b9d-bbbd-83cc-aede-5b8c59848f96",
"when":1727723964,
"file":"_health.qo",
"body":{
"text":"boot (brown-out \u0026 hard reset [16888])",
"voltage":4.890625
},
"session":"9b5e0471-9e23-4b06-86d2-f8094ad92f0a",
"best_id":"dev:864049051550715",
"device":"dev:864049051550715",
...and so on...While there can be a lot of interesting insights derived from the metadata of
each event stored in Notehub, you may only care about the body, timestamps,
and/or location of each event. Just like with Notehub routes, you can use
JSONata
(or manually process the JSON yourself) to limit the data that will eventually
be sent to the OpenAI APIs.
Why not just send all of the event data? Two reasons: The more specific you are with your AI prompts and data you deliver, the more accurate and "hallucination-free" the responses should be. Also, the less data you send, the fewer billing tokens you will consume from OpenAI. You'll have to find the right balance for your scenario.
Using the OpenAI APIs
Assuming at this point that we have pulled a set of events to interpret, it's time to use AI to process this data. This is where everything gets a bit fuzzy, because there isn't one perfect way to execute everything I'm about to show you. However, it's easier than you may think to get started!
OpenAI is the industry leader in artificial intelligence and machine learning technologies (it's likely many of you have used their flagship product ChatGPT).
We're going to focus our time on the Chat Completion API which creates responses from the chosen LLM based on the data/prompt that we send.
To get started, you'll need to create an account on the OpenAI Platform.
Using this API requires the following inputs:
- An OpenAI API key (which you can generate from the API Keys option via the main Settings menu).
- A "system" or "developer" prompt, which is a command appended to all requests. This overrides the user-provided prompt below, allowing you (as the developer) to enforce certain guardrails. For example, my system prompt is to "Act as a data scientist" which tells the LLM to assume a specific role when interpreting data.
- A "user" prompt, which is essentially the question(s) our end users might ask about the data. An example user prompt might be "Identify any anomalous data points, interesting trends, or otherwise notable events from the provided data".
- The model (LLM) we want to use. While there are
plenty of options, I suggest
starting with
gpt-4o-minias it balances accuracy with a reasonable price. - The maximum number of billing tokens to use. The more tokens you
allocate, the more data you can send (input tokens) and receive (output
tokens) in a given request. This value is up to you, but you can start with a
low number of
300.
Be sure to consult the OpenAI documentation for a full list of API arguments.
Here's an example generic Chat Completion API request from the OpenAI docs:
curl "https://api.openai.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-4o",
"messages": [
{
"role": "developer",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Write a haiku about recursion in programming."
}
]
}'And here is the corresponding C# method I built to ask questions of my event data:
protected static string GetOpenAIAPIResponse(string userPrompt, string inputText)
{
string apiKey = "my-openai-api-key";
string apiUrl = "https://api.openai.com/v1/chat/completions";
string prompt = userPrompt + " " + inputText;
var requestBody = new
{
model = "gpt-4o-mini",
messages = new[]
{
new { role = "system", content = "You are a data scientist. Return your response in HTML, but only return the body element." },
new { role = "user", content = prompt }
},
max_tokens = 300
};
string jsonPayload = JsonConvert.SerializeObject(requestBody);
try
{
using (var client = new HttpClient())
{
client.DefaultRequestHeaders.Add("Authorization", string.Format("Bearer {0}", apiKey));
var content = new StringContent(jsonPayload, Encoding.UTF8, "application/json");
HttpResponseMessage response = client.PostAsync(apiUrl, content).GetAwaiter().GetResult();
string responseContent = response.Content.ReadAsStringAsync().GetAwaiter().GetResult();
JObject json = JObject.Parse(responseContent);
// extract the "content" field only!
string theContent = null;
JToken choices = json["choices"];
if (choices != null && choices.HasValues)
{
JToken firstChoice = choices[0];
if (firstChoice != null)
{
JToken message = firstChoice["message"];
if (message != null)
{
JToken contentToken = message["content"];
if (contentToken != null)
{
theContent = contentToken.ToString();
}
}
}
}
return theContent;
}
}
catch (Exception ex)
{
throw new Exception(ex.Message);
}
}The response from the API is (of course) in JSON:
{
"id": "chatcmpl-AsvoOfXv1WID3nIrEezj8Slcx6kGG",
"object": "chat.completion",
"created": 1737655304,
"model": "gpt-4o-mini-2024-07-18",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "<body>\n <h2>Data Analysis Report</h2>\n <h3>Anomalous Data Points</h3>\n <ul>\n <li>\n <strong>Voltage Drop:</strong> The voltage readings show a significant drop in some entries. For instance, the voltage decreased from 4.4648438 to 3.7558594 between two consecutive entries, which may indicate a potential issue with the power supply.\n </li>\n <li>\n <strong>Temperature Variability:</strong> The temperature fluctuates significantly, with a high of 26.25°C and a low of 8.6875°C. This could suggest environmental changes or sensor inaccuracies.\n </li>\n </ul>\n \n <h3>Interesting Trends</h3>\n <ul>\n <li>\n <strong>Journey Consistency:</strong> The journey ID 1733504386 appears multiple times with varying motion counts and temperatures, indicating a consistent tracking of a specific journey.\n </li>\n <li>\n <strong>USB Status:</strong> Several entries indicate a \"usb\" status, suggesting that the device was connected to a power source during those times, which may correlate with higher voltage and temperature readings.\n </li>\n </ul>\n \n <h3>Notable Events</h3>\n <ul>\n <li>\n <strong>High Motion Count:</strong> The entry with a motion count of 14 and a temperature of 26.25°C suggests a period of high activity, possibly indicating a significant event or change in the environment.\n </li>\n <li>\n <strong>Long Duration:</strong> The entry with a journey time of 1723 seconds indicates a prolonged period of tracking, which may be relevant for understanding the behavior over time.\n </li>\n </ul>\n</body>",
...and so on...If you look closely at the C# method above, you'll see that I only return the
contentelement, which is the full text response from the LLM.
To tie everything together, I built a simple web form uses all of the methods above and binds them to a single UI:

And the output of these prompts? Here is what OpenAI had to say about the event
data derived from my _track.qo Notes:
Anomalous Data Points
- Voltage Drop: The voltage readings show a significant drop in the last few entries, particularly from 4.4648438 to 3.7558594.
This could indicate a potential issue with the power supply or battery.
- Temperature Variability: The temperature readings fluctuate significantly, with values ranging from 8.6875 to 26.25. The low
temperature of 8.6875 could be considered anomalous compared to the other readings.
Interesting Trends
- Journey Consistency: The journey ID 1733504386 appears multiple times with varying motion counts and temperatures, indicating a
consistent tracking of a specific journey.
- USB Status: Several entries indicate a "usb" status, suggesting that the device was connected to a power source during these
readings, which may correlate with higher voltage and temperature readings.
Notable Events
- High Motion Count: The entry with a motion count of 14 during journey 1733509102 suggests a period of high activity, which may
be worth investigating further.
- Long Duration: The entry with a duration of 1723 seconds indicates a prolonged event, which could be significant for understanding
the context of the data.Summary
It's almost too easy isn't it!?
While it's just a first step, I hope you've gotten a hint of what is possible by processing your product's data with an LLM. Check back throughout the year as we at Blues explore this more and help you unlock insights into your connected products.